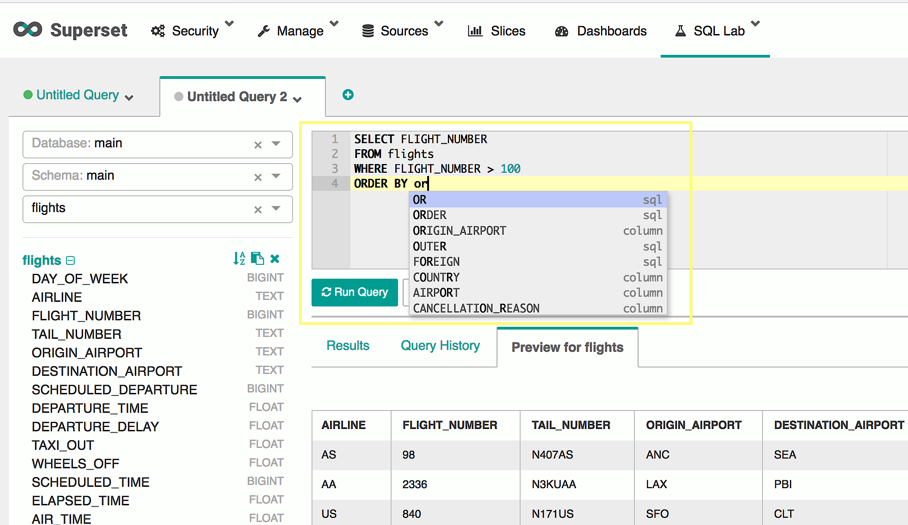
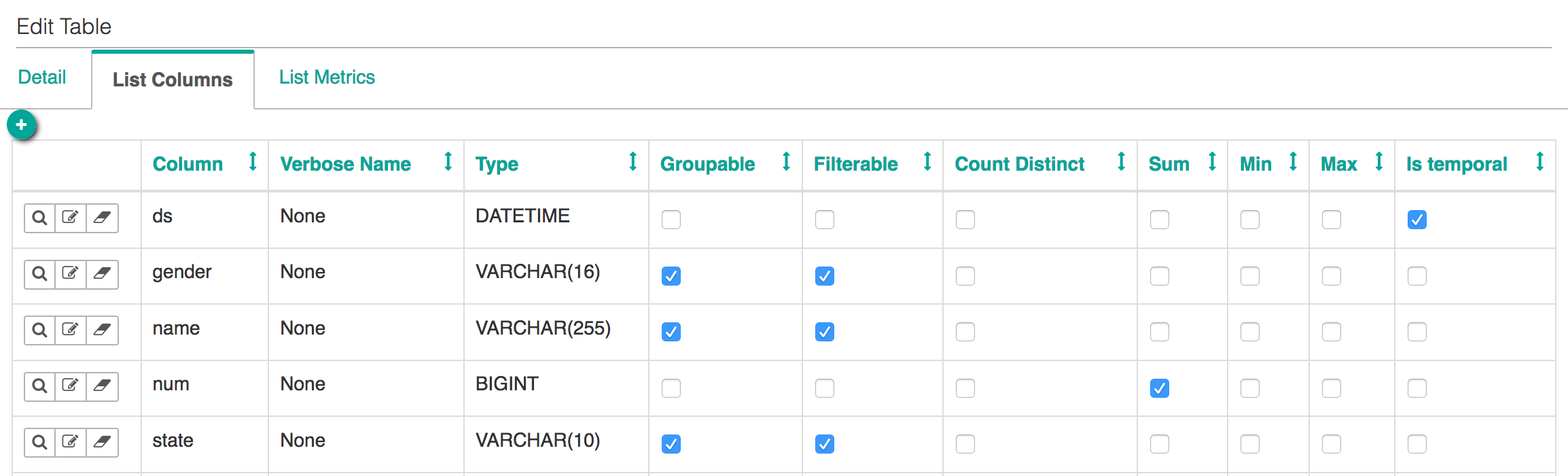
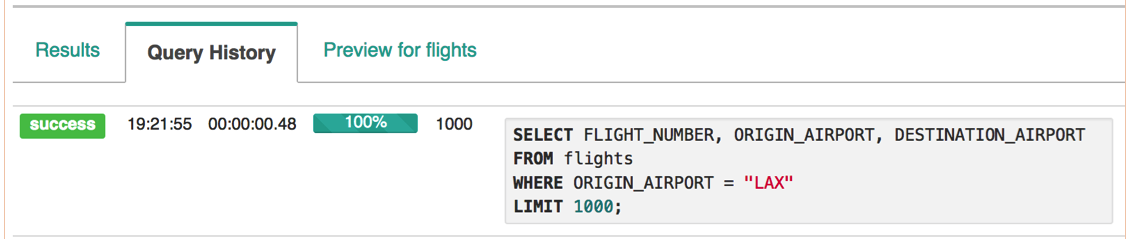
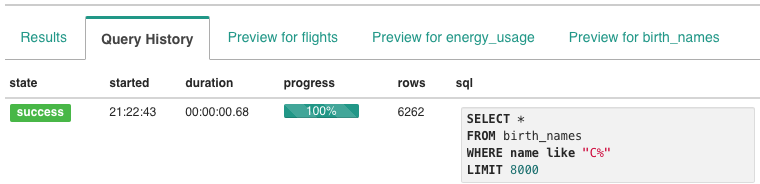
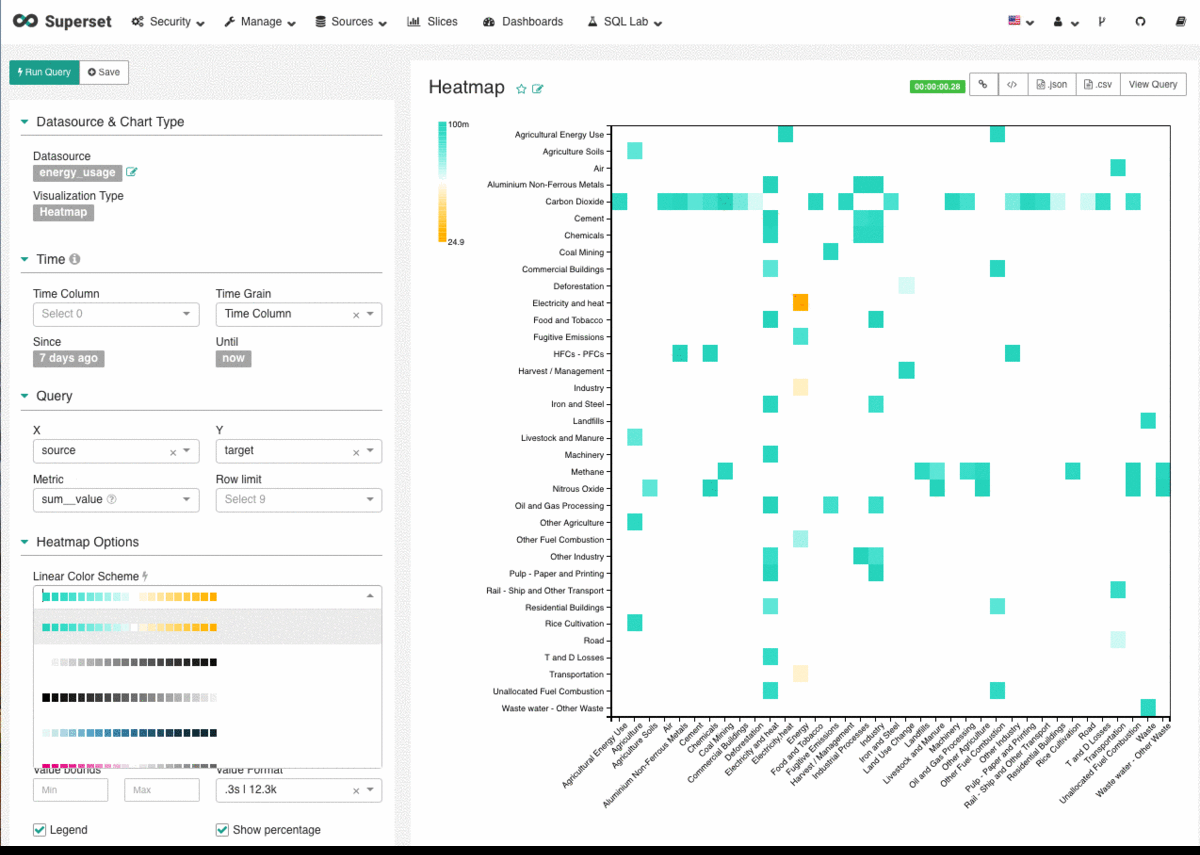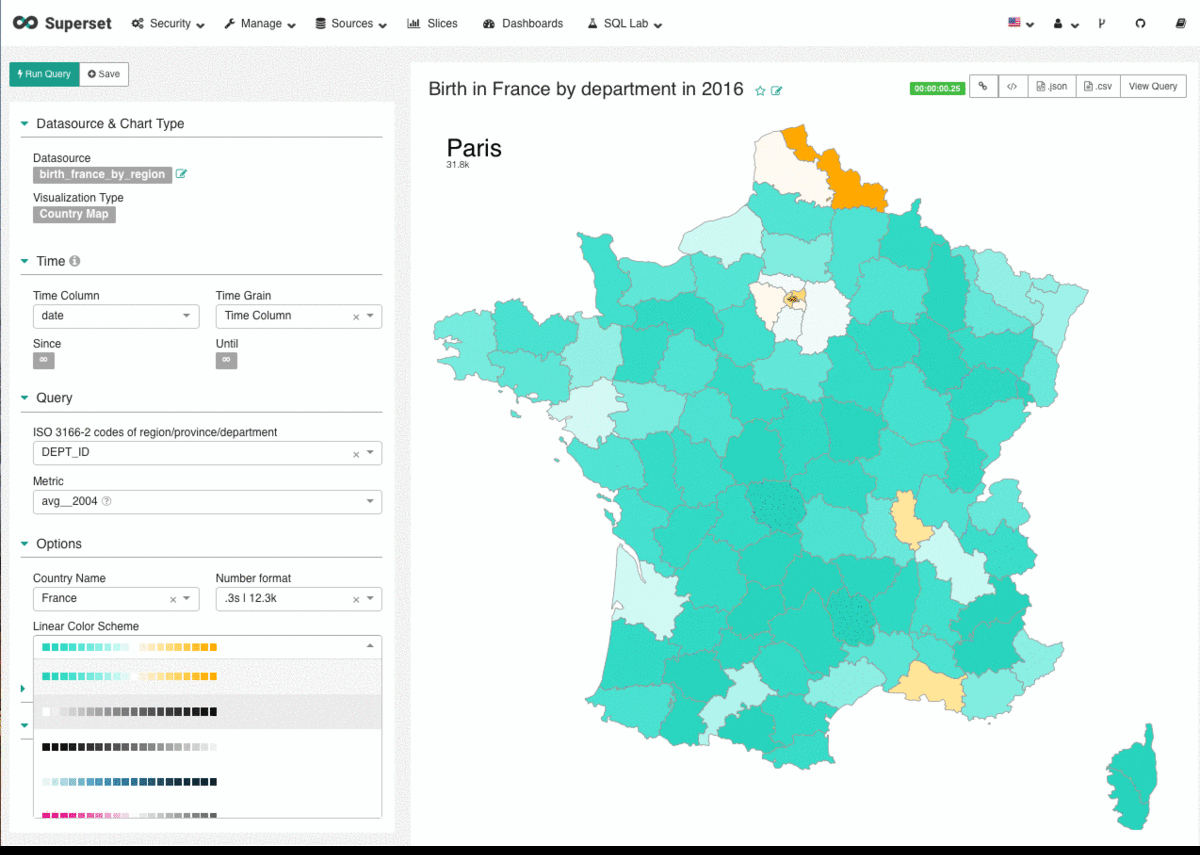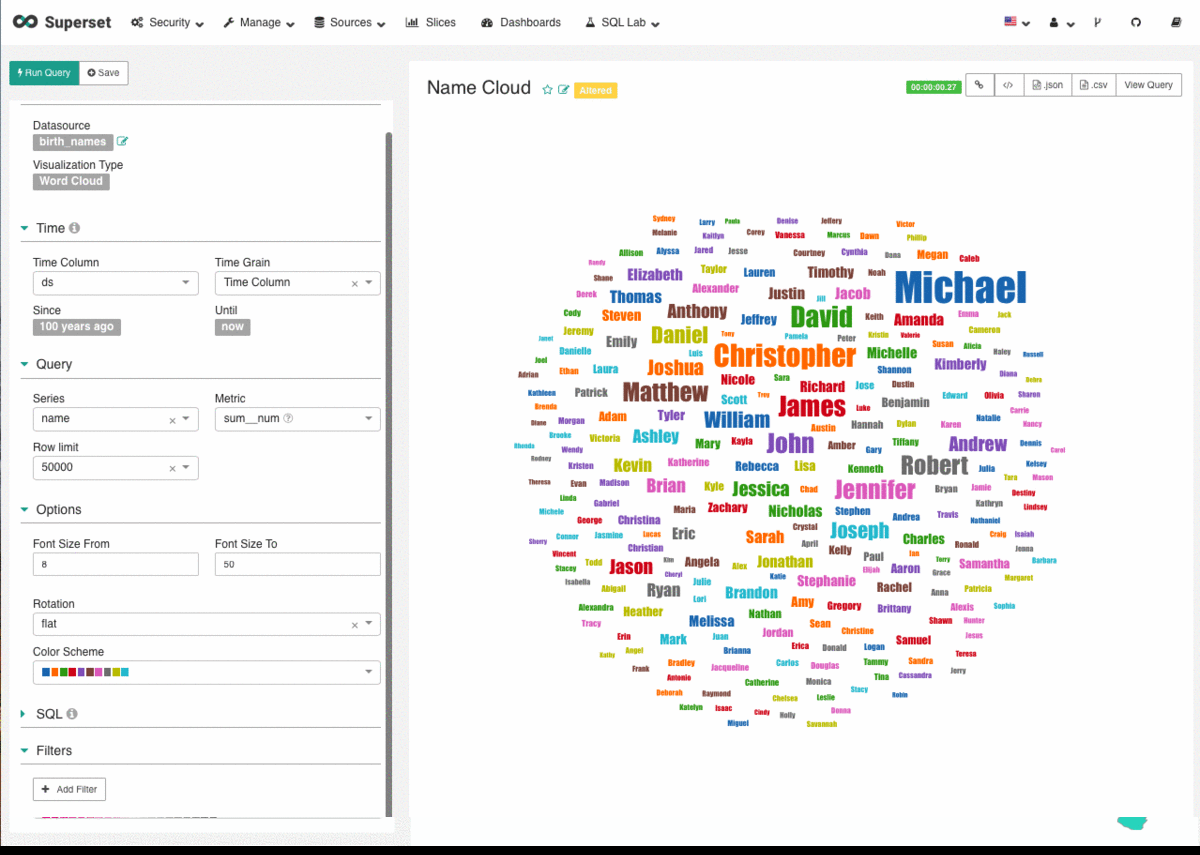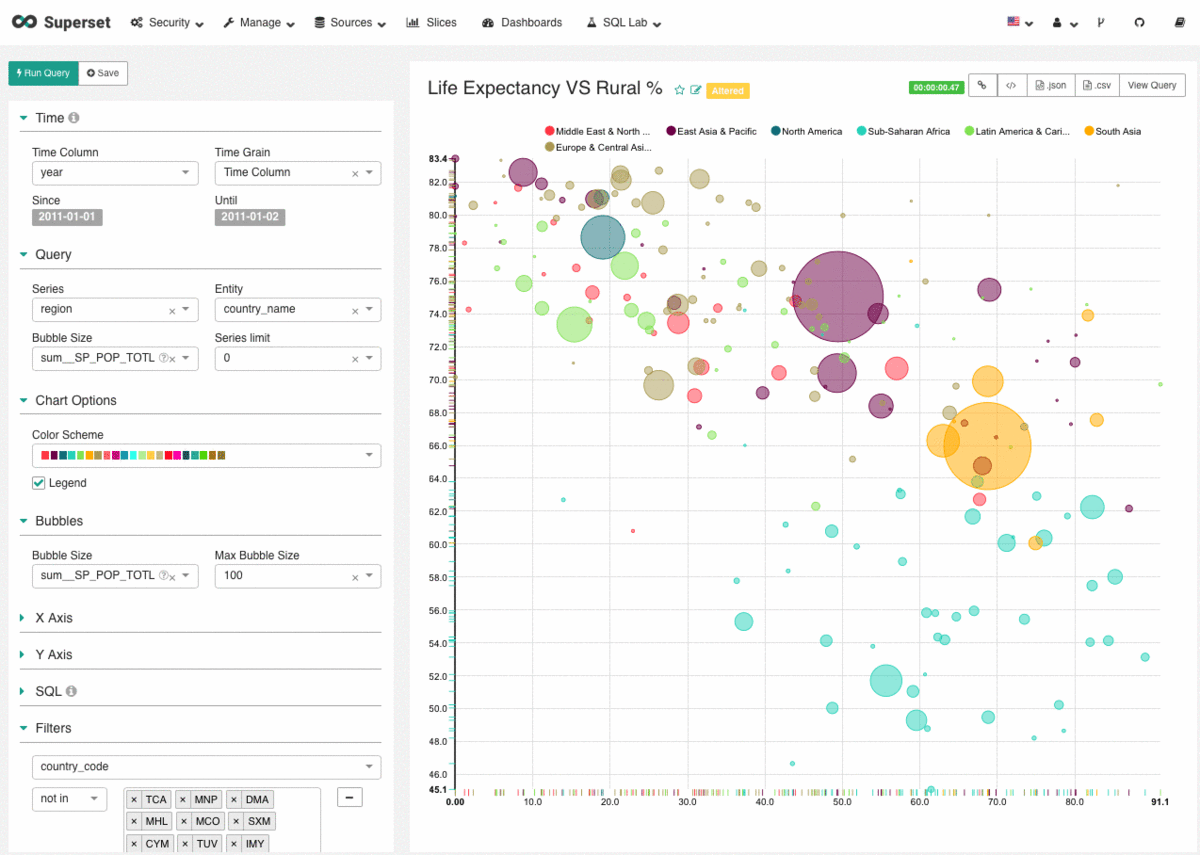
Machine Learning has been developing further every day, thanks to the digital transformation movement. The original basis was a theory that believed computers could learn to perform specific tasks and to recognise patterns. The challenge was simple: to check if computers could learn from data.
Machine Learning provides systems with the possibility to learn and improve from experience, without needing specific programming for that effect. The focus is on developing programs that use available data and can learn on their own. The mathematical models are built and powered with – potentially – large amounts of data. The algorithms learn to identify patterns and to extract insights that are applied when new information is processed. This term dates back to 1959, when the pioneer Arthur Samuel defined Machine Learning as the ability of a computer to learn without being explicitly programmed to do so.
This learning process starts with data processing and trying to identify patterns. The main goal is to allow computers to learn autonomously without the need for human assistance, using that knowledge to make decisions according to what was “learnt”. Even though machine learning algorithms have been around for a long time, the application of these mathematical calculations to Big Data, with more frequency is a recent development. However, according to industry reports, what is considered to be an exponential growth in this area today is going to be seen as only “baby steps” in 50 years. This AI field is expected to grow extremely fast in the coming years.
Examples of Machine Learning
The continuing interest in this practice stems from a few key factors that have also made data mining and Bayesian analysis extremely popular: growth in the volume and variety of available data; cheaper and more powerful computational processes; and low cost storage.
A few examples of machine learning applications in some companies include self-driving vehicles; recommendations from online platforms such as Amazon and Netflix based on users’ behaviour; voice recognition systems such as SIRI and Cortana; PayPal’s platform, which is based on machine learning algorithms to fight fraud by analysing large quantities of data from the customer and assessing risks; the model from Uber that uses algorithms to determine time of arrival and departure locations; SPAM detecting mechanisms in email accounts; facial recognition that occurs in platforms such as Facebook.
Industries that are choosing Machine Learning
Most industries with large amounts of data have already acknowledged the potential of this technology. The possibility to extract insights allows companies to obtain a competitive advantage and work more efficiently.
Financial Services
Banks and other financial entities are using machine learning with two goals: extracting valuable insights from customer data and preventing fraud. Insights identify investment opportunities according to customers’ profiles, and, concerning fraud, the identification of high-risk customers and suspect transactions is improved.
Furthermore, this technology can also influence customer satisfaction. By analysing a user’s activity, smart machines can predict, for example, a possible account closure before it happens and prompt mitigating actions.
Health
Health entities can capitalise on the integration between IoT and data analysis to develop better solutions for patients. The emergence of wearables allows acquiring data related to the patients’ health, which, in turn, allows health professionals to detect relevant patterns including risk patterns. Therefore, this technology offers the potential for better diagnosis and treatment.
Retail
Nowadays, the impact of smart machines in users’ retail experience is quite obvious. The result is a highly personalised service that includes recommendations based on purchase history or online activity; improvements in customer service and delivery systems, where machines decipher the meaning of users’ emails and delivery notes, in order to prioritise tasks and ensure customer satisfaction; and dynamic price management by identifying patterns in price fluctuations and allowing to prices to be determined according to the demand. The ability to gather, analyse and use data to personalise, for example, a purchase experience (or implement a marketing campaign) is the future of retail.
Transportation
Analysing data to identify patterns and trends is key to the transportation industry, since profit growth means more efficient routes and the projection of potential problems. Data analysis and the modelling aspects of machine learning are important tools for delivery companies and public transportation, allowing them to improve their income.
Machine learning apps allow companies to automate the analysis and interpretation of business interactions, extracting valuable insights that make personalising products and services, possible.
Xpand IT has a complete service portfolio in Machine Learning. If you want to know how to use Machine Learning in your business and obtain real added value, we can help. Do you want to know how we can help your business? Contacts us here and get the best out of this technology!